
This year we decided to go to SXSW. It’s been a couple of years since last time, so I really hoped that the artist lineup and music schedule would be more comprehensible than it was last time we went. It wasn’t. To make sense of all this data, it needs personalization. Humans tend to be very specific when it comes to their taste in music, so just having a list of a couple of thousand artist names doesn’t cut it.
Since there were no other services available I figured that even a poor one could help people like ourselves. I started by scraping the SXSW website (5 lines of sloppy php):
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| <?php | |
| $artist_html = shell_exec('curl "http://schedule.sxsw.com/2017/artists"'); | |
| preg_match_all('!<h4><a href="(.*?)">(.*?)</a></h4>!', $artist_html, $matches); | |
| foreach($matches[1] as $i=>$val){ | |
| print_r($matches[2][$i]." : ".$val."\n"); | |
| } |
Once we got the data from the SXSW website, it needs to be mashed with some Spotify metadata:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| <?php | |
| # fetch and cache artist id by doing a search | |
| $spotresults = @json_decode(shell_exec('curl "https://api.spotify.com/v1/search?q='.$artistNameFromScrape.'&type=artist" -H "Accept: application/json"')); | |
| $artistmeta = json_encode($spotresults->artists->items[0]); | |
| $artistid = (string)$spotresults->artists->items[0]->id; | |
| $artistname = (string)$spotresults->artists->items[0]->name; | |
| $result = $db->prepare("INSERT INTO artists(artist, url, parent_artist, json) VALUES(?,?,?,?)"); | |
| $result->execute(array($artistname, $val, 0, $artistmeta)); | |
| $insert_id = $db->lastInsertId(); | |
| # fetch and cache related artists | |
| if($artistid){ | |
| $spotresults = @json_decode(shell_exec('curl "https://api.spotify.com/v1/artists/'.$artistid.'/related-artists" -H Accept: application/json')); | |
| if($spotresults->artists){ | |
| foreach($spotresults->artists as $currartist){ | |
| $result = $db->prepare("INSERT INTO artists(artist, url, parent_artist, json) VALUES(?,?,?,?)"); | |
| $result->execute(array($currartist->name, '', $insert_id, json_encode($currartist))); | |
| } | |
| } | |
| } | |
Haha I know! This is very poor code. Using MySQL as a cache… It’s amazing how such a good result can be made with such bad practices. I would (probably) never do this for a client, but for a sloppy side project like this – sure.
Anyway. Now when we’ve got all artists playing at the festival, and all the related artists, all we need is for people to sign in using Spotify’s oauth, fetch their top artists and do some id matching in our MySQL database to see what artists to recommend.

An added bonus was to automatically create a playlist in the user’s Spotify account. This required two more API calls, first create an empty playlist and then add all the track uri’s.
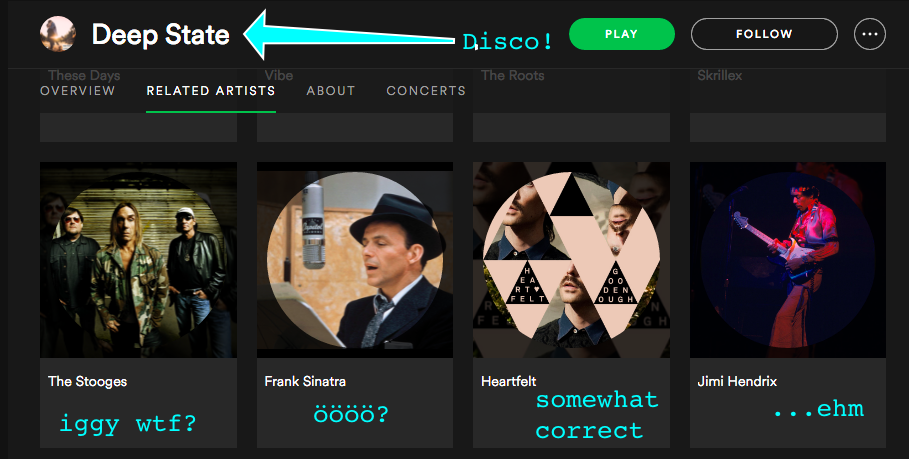
Some gotchas in the Spotify API we’ve learned (this might be bad advice, absolutely no idea…):
a) SXSW artists are often “up and coming” and have less than 1000 listens on Spotify. This makes Spotify unsure…
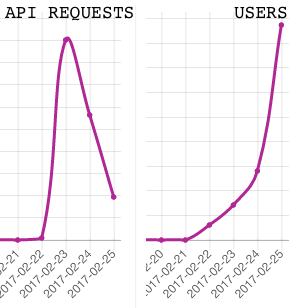
b) Rate limiting is real. When making lots of requests, be sure to sneak in a sleep(1) here and there. Seems to help.
c) Don’t sign requests you don’t need to sign. Since rate limits are counted towards your app id, this is a neat way of sneaking in some extra requests. Stuff like searching for related artists doesn’t currently require authentication.
d) Cache as much as you can before releasing your app. Fetching top tracks for 50 artists synchronously makes you hit the rate limit, and it will also hit your server’s network IO hard if you have a lot of simultaneous users. In this case we had a fixed set of artists, so it made sense to prefetch all their top tracks in a local db.
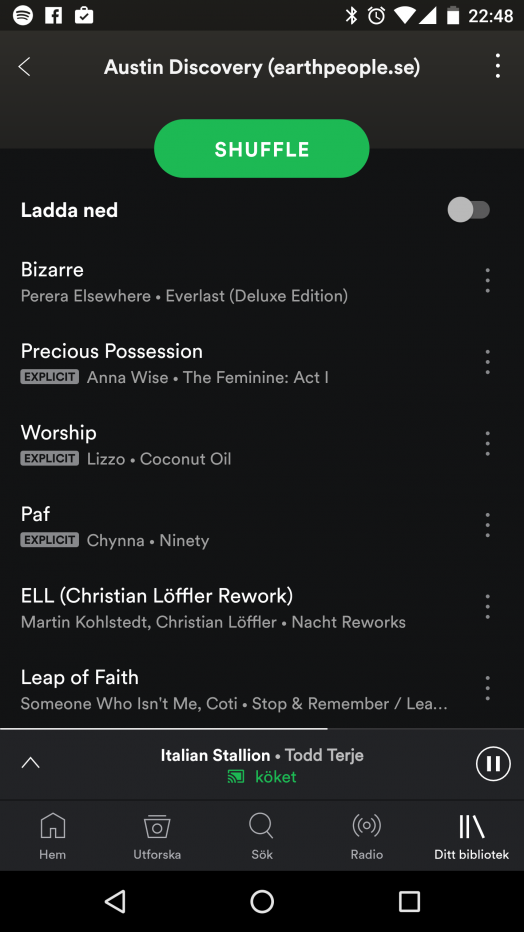
Sidenote: We deliberately chose to not name this service after SXSW to avoid trademark infringement. It’s called austindiscovery.earthpeople.se.
/Peder
Comments
One response to “SXSW Music Discovery”
Tack darlings! <3