Du är besökare 20175
-

The making of Red Bull Secret Gig x Robyn
So we made a game for Robyn and Red Bull Music. This is the second post in a series of posts about this. Here our UX Designer Nana talks about designing a competition for the compassionate, and the secret ingredient to a sticky game. Post nr 1: Making the server side… Post nr 2: This…
-
Lessons from making the server side to Red Bull Secret Gig X Robyn
So we made a game for Robyn and Red Bull. This is the first in a series of posts about this. Here we focus on the server side and outline some of the challenges we had. Post nr 1: This post. Post nr 2: The making of… Post nr 3: The design of… While the…
-
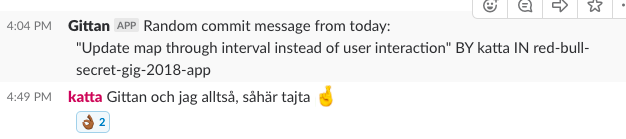
Skriv bättre commit-meddelanden med hjälp av Gittan
Jo, men för ett år sedan skrev vi överlag rätt dåliga commit-meddelanden. “Fix” och “Stuff” var inte helt ovanligt att läsa i historiken. Problemet med sådana meddelanden är att de inte ger nånting; att komma in som ny utvecklare i ett projekt fullt av “Fix” är minst sagt lite knepigt. För att få alla att…
-
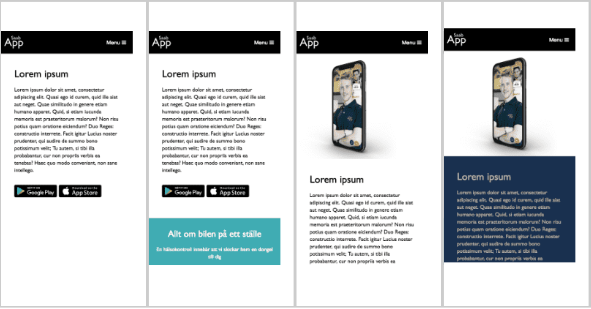
📸 PushSnapper visualiserar utvecklingen av våra webbplatser
Vid utveckling av webbplatser gillar vi att få en visuell historik över sajtens utveckling. Allt från en första vit blank sida till en färdig sajt med logotyp, menu, content och (ibland) andra färger än vitt. För att få denna historik har vi utvecklat ett eget verktyg vid namn 📸 PushSnapper. En skärmdump vid varje deploy…
-

Hämta hem ISRC-koder och annan matnyttig metadata du inte kan se i Spotify-appen.
Vi är ett antal individer på det här bygget som släppt ifrån oss musik i olika former. Jag själv började trevande med cdr-släpp med hemgjorda omslag, la ut musik i låg bitrate när MySpace-eran nådde zenit, för att gå vidare till “riktiga” cd-skivor, vinyler och de streamingtjänster som vid det här laget känns som de…
-

Gör en Spotifyplaylist från vilken sida som helst på hela Internet
En kanske gillar en del program på Sveriges Radio och en del musikbloggar. Dessa har massor med fina låtar listade, en och en, på sina websidor. Fantastiska playlists, förutom att de inte är just playlists utan bara låtlänkar. En vill inte sitta och klicka play låt efter låt utan ha detta i playlists istället. Märkligt…
-

Hur man gör en användbar flamingo-badring till Roblox
Sommarpyssel för dig och din unge. Det låter kanske kul men det är ett litet helvete. Fast jo, också kul. Roblox är en spelplattform med en egen utvecklingsmiljö för publicering av egna spel. Det har funnits sedan 2006 men på senaste tiden har det ökat snabbt i popularitet och är enormt stort i den yngre målgruppen…
-
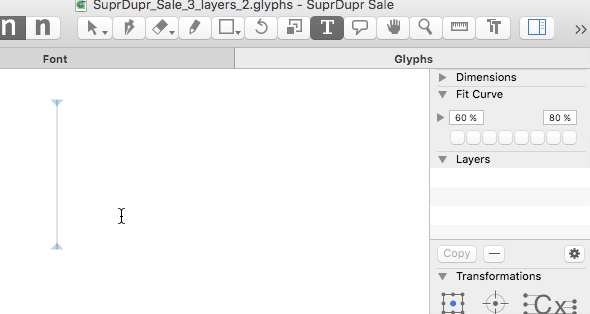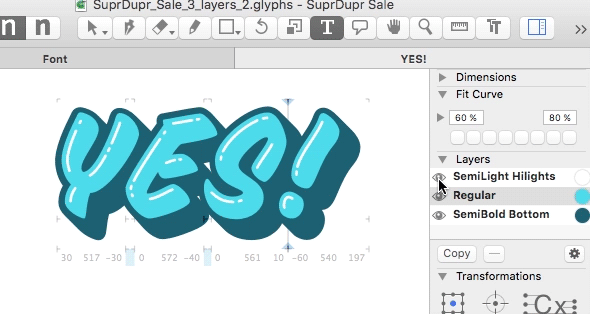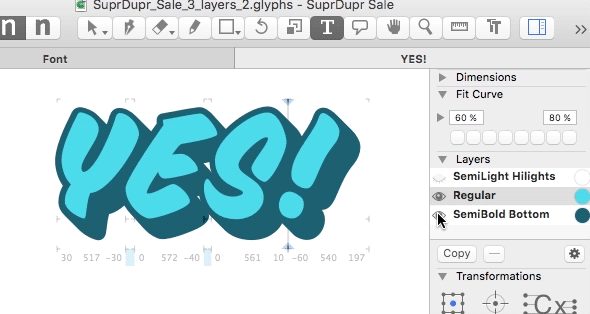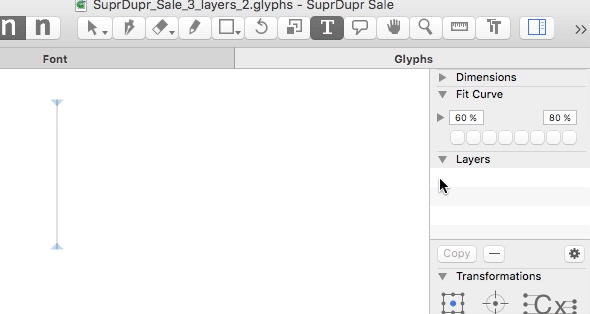
Typsnitt med flera lager?
Typsnitt med flera lager – layered fonts. Vad hände med det egentligen? Det var ett par år sedan jag labbade med det sist. Och tekniken har ju funnits i flera år innan det. Det har funkat väldigt tillfredsställande att jobba med det i Glyphs men andra programvaror har fortfarande begränsad support. Glyphs är iofs en programvara för…
-

Blipp Blopp för barn
Förra året gjorde vi ett kul sidoprojekt som inte nämnts här: Blipp Blopp för barn – som blev grammisnominerad som “Bästa barnalbum”! Barn behöver roligare kultur, och vad är roligare än pruttande syntar, fula röstljud och robotdans. Blipp Blopp för barn är en elektronisk barnskiva släppt på vinyl och digitalt, Earth People har agerat skivbolag. Andreas gjorde omslagsballonger…
-
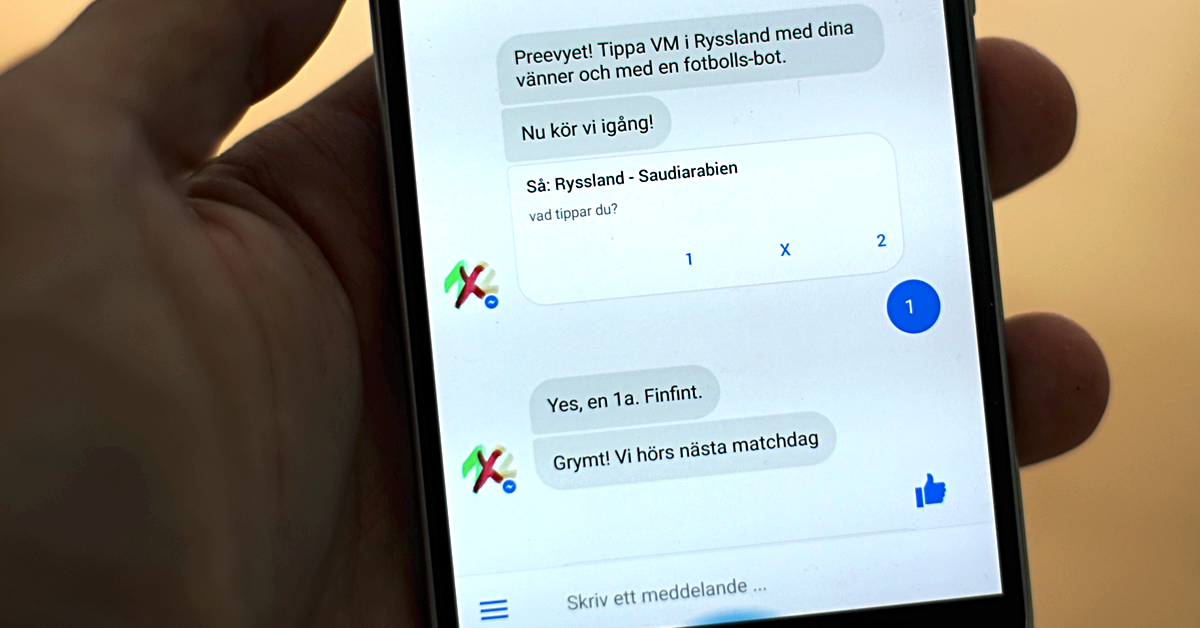
Tippa Fotbolls-VM i en chatbot
Nu drar Fotbolls-VM 2018 igång och vår bot i Facebook Messenger för 1×2-tippning som vi gjorde till Euro 2016 får nytt liv. Chat-plattformen passar definitivt inte allt, men här glänser den faktiskt som en liten diamant. Enkelheten att komma igång, utan att ladda ned något eller skapa ett konto, få en liten ping varje matchdag och snabbt…
-

Pinga-mig-när-jag-missat-botten
Vi jobbar ju i en del projekt där faktiskt nedlagda timmar ska faktureras. Men det är ju så roligt att jobba och så himla svårt att komma ihåg att tidrapportera, även om man som vi gör det direkt i Slack. Men samtidigt dumt att bjuda på timmar som glöms. Så jag hackade ihop en liten slackbot…
-

Jenny Wilson – EXORCISM release fest
Alltså oklart varför, vi är ju ingen eventbyrå. Men i mars ordnade vi ändå en skofri releasefest i dansens tecken, för Jenny Wilsons nya skiva Excorsism. För att: 1) det är så sjukt kul att ordna fester. 2) så himla fint att sammanföra massa bra folk från vårt nätverk som kan bidra med sina specialiteter. (Video: Ola…