
We have provided data from the Moody database to a group of researchers in the Netherlands, who have been doing some really interesting work. Menno van Zaanen gives us a report:
As a researcher working in the fields of computational linguistics and computational musicology, I am interested in the impact of lyrics in music. Recently, I have been researching what makes a song fit a particular mood. Why do we find some songs happy and others sad? Is it mainly the melodic part or mainly the lyrics that make the mood of a song? Do we agree upon this feeling or, in other words, do we consistently assign a mood to a song?
In particular, I am interested in building computational models that allow us to automatically assign a mood to a particular song. If we can successfully build such a model, we can also build a system that can filter songs from a large music collection based on their mood. For instance, your music player can create a playlist containing only happy songs by analyzing the songs in your music collection without manual interaction. Without such a system, people would need to listen to each song and indicate its mood by hand.
When building a computational model of mood in musical pieces, we need to have access to data. For instance, when we want to evaluate our model, we need musical pieces for which we know the corresponding mood, so we can check whether our model assigns the same mood as people have. Additionally, we use annotated data (songs together with their mood) as training data. This allows us to fine-tune our models to human preferences.
The data that we require for our computational model has to be annotated by people (as we are trying to model their preferences). Fortunately, the data collected using the Moody application fits our purposes exactly. People annotate their music into mood classes, which encodes information on what people think of these songs. This information is stored in a database for which the Moody plug-in acts as a graphical user interface.
The first dataset I received from the Moody database contained a list of songs, artists and mood tags, which I call the Moody Tags dataset. There is a total of 16 possible moods, which can be represented in a two-dimensional plane. One axis describes the valence, or polarity, of moods and the other axis describes arousal, or amount of energy. This looks exactly like the kind of information one needs when building a computational model of mood preferences.
While working with the Moody Tags dataset, I wondered in how far people consistently assign mood tags to music. The answer to this question cannot be found in the Moody Tags dataset, as there is only one tag assigned to each song. How exactly is this tag selected, taking into account that multiple people may annotate the same song with different mood tags?
It turns out that in the Moody database, tag counts are stored that describe for each value on the two axes, how often that value has been used to tag that particular song. Effectively, the Moody Tags dataset provides the tags that fit with the most often tagged value for both of the axes for each song. The raw counts of the tags can be extracted from the database as well and I will call that dataset the Moody Counts dataset.
Based on the Moody Counts dataset, I can analyze in how far people agree with each other when assigning mood to a song. Normally in the area of annotation, one would measure the amount of agreement, which is called inter-annotator agreement, using a metric such as Cohen’s Kappa or Krippendorff’s Alpha. Unfortunately, in this case, these metrics cannot be used, since I do not know exactly which annotator (user) tags which songs. Therefor, I need to come up with other metrics.
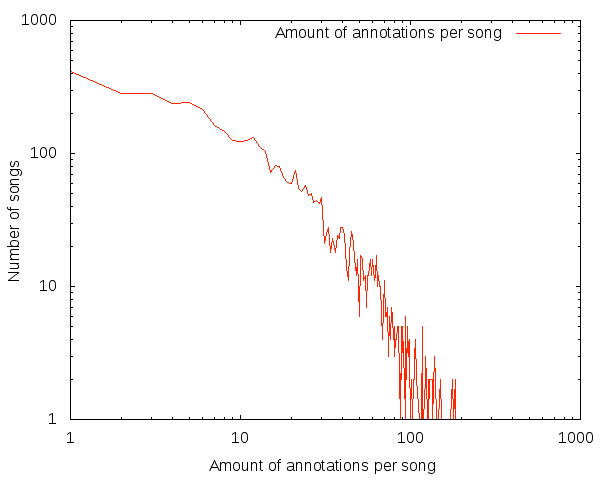
To make sure the dataset has enough annotations per songs, I checked the average number of annotations per song, which is approximately 19. The distribution of number of annotations per song can be found in the figure above. On the x-axis you can find the number of annotations per song and on the y-axis the number of songs with that many annotations. As you can see, there are just over 400 songs with only one annotation, but there are also songs with over 100 annotations.
Next, I check the percentage of songs that have only one mood assigned to it. This holds for 56.5% of the songs. However, it is a bit unfair to only provide this measure. First of all, there are quite a few songs that have only one annotation, which means that there can only be one mood assigned to these songs.
Computing the average percentage of the majority tag (which is the number of annotations of the most often selected mood divided by the total number of annotations for that song), shows that for both the arousal and valence dimensions this amounts to just over 95%. Again, here I am also using the songs with only one annotation, but if I remove these songs, so only take songs with two or more annotations into account, the percentages are still over 94%. Even when I only take songs into account that have 50 or more annotations, these percentages are over 91%.
Based on the data I have available at the moment, it seems that people tend to agree on the mood songs have. This makes it an interesting topic to research. Now we know that people generally agree, can we actually build a system that does this for us and will this system also be as consistent as we are in assigning mood to songs? Obviously, before we can actually answer this question, there are many other questions we need to answer first: What exactly contributes most to the mood of a songs, is it the melodic part or the lyrics? What properties of either melody or lyrics contribute most to the mood of a song? With datasets that are collected by applications such as Moody we may, at some point in the future, find out exactly how people perceive the mood of music.
Menno van Zaanen
Assistant professor at Tilburg University, the Netherlands
Comments
2 responses to “Extracting mood data from music”
Hello,
This is very interesting. Actually I’m working currently on a similar topic: music classification by mood. I liked your analysis for the database. It seems that out of the info you got from moody, you made your own song-mood (song – highest frequency annotation) data-set. Do you have this dataset available for research work?
Thank you.
Hi,
I’m a computer science student and I’m working on a music classifier neural network which sorts wav files in two categories: happy and sad. It is very difficult to found a good dataset which could be used for teaching the neural network. I already build a dataset with 136 input values, but it is too small to teach the neural network efficiently. I need more data to make the classification more accurate.
I would like to ask you if it is possible to share your dataset with me? It will be used just for educational purposes.
I’m looking forward to hear from you!
Thanks,
Csaba