Earth People was approached by Forsman & Bodenfors to make a Digital Out Of Home (DOOH) screen come to life. The objective of the campaign was to showcase the client’s eye makeup products. The eyes were shot in 4k and our task was to make these eyes “look” at any motion in front of the screen.
Kinect to the rescue! Or?
We quickly agreed that Kinect would be the most suitable choice regarding tracking since Kinect 2 provide API’s for body tracking. After much trial and error we realized that the Kinect had too many cons versus pros in our case.
First of all; the hardware. In order to get any decent performance out the Kinect we needed a computer powerful enough to calculate the incoming data. This meant that our hardware footprint would be huge. Much too big for our tiny available space within the outdoors screen.
Secondly; speed. Kinect is meant to be enjoyed at home with a small group of people. There is time to move around the room to place you in such a position that the Kinect would recognize you and start calculating/tracking your body movement. We don’t have that kind of time when people are just passing by.
I’ve done several projects in the past using tracking and I knew that it would be possible to get good enough result using a plain old webcam. We don’t need 4K video or pin-point accuracy in this case. We just need to know where people are, if there are any at all, in front of the screen.
Processing image data
![]()
Our solution for tracking comes in ~4 steps which are, by themselves, quite straight forward.
1. Get the raw webcam feed
This is a walk in the park easy. In our case we use processing and retrieve the webcam data using the standard Capture library.

2. What has changed?
Storing the previous frame from the webcam we can calculate the difference between the pixels of the current frame and the previous. This gives us a rough idea of what is going on in front of the camera. Doing this using bitwise operations gives us more processing power for our next computation.

3. Normalize the result
The data we get from the difference calculation is very noisy and blurred. This is due to the motion. In order to proceed we need to sanitize the output, removing “dust” and tiny pixel-changes. The small changes is probably not a person walking by anyway. The “clean” data from our normalization (or threshold) process is a great start but produce high level of motion all over the place. In this example, my t-shirt is moving a lot but we don’t necessarily want to track that.
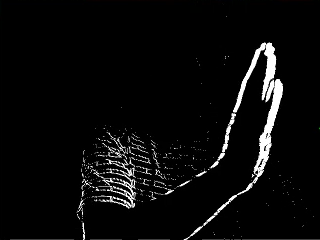
4. Predictions
We know that high concentration of motion should be clustered together. My hand moving is producing much greater change than my t-shirt. By looking at each individual white pixel in our normalized output we can connect that pixel with the white pixels immediately surrounding it. Doing this recursively and by registering a new cluster of pixels when we no longer find any white pixels next to the cluster, we get a long list of isolated clusters we call “islands”.
The amount of data to process is still enormous. We need to boil this down, quickly. Here’s what we did; each cluster that is less than roughly 200 pixels is discarded immediately. In this example, we reduced the amount of islands from well above 150 down to about 5. This is still too much data for us to estimate where the motion is coming from. A last attempt to reduce the number of islands is brute-forced, merging any island covering another island measured by their bounding box (highlighted in green).
![]()
The largest island contain the most motion. This is what we are interested in.
5. What should the eyes look at?
This is not really tracking related but in order to get a single point of interest for our 15 eyes to look at we need to be more specific than “this island looks good enough”. Each time we receive a new island to focus on, we place a vector in the center of that island. This is our target. Our current focus vector is then moving closer to that target each frame, using a decay value so that we never actually reach the final target position.
What more can we do with this data?
Since we know how many pixels are changed between each frame, we can set a threshold of how many pixels that needs to contain motion before we proceed. If we never reach that threshold we may consider the current image as empty. No motion = no people = no need to process the image further.
There are many more things going on behind the scene but this should give a glimpse of what we ended up with and why.