Du är besökare 20175
-

Klubben Webbklubben
Jag kom på nu att vi ju kört rätt fina afterworks hos oss i gamla stan, i flera år, och glömt berätta om dessa. Om du känner oss sedan tidigare kanske du varit här, annars är du välkommen i framtiden. I sin enkelhet bjuder vi på öl och bokar en artist vi lyssnat på. Det…
-

Politiker goes influencer
Influencers tjänar mycket pengar. Politiker tjänar mycket pengar. Så hur tjänar man asmycket pengar? Var både politiker och influencer på samma gång! Hur skulle detta se ut då? Jag byggde en fejksajt som ser ut som instagram.com där jag hämtar in data från våra mest kända influencers och byter ut namnen mot kända politiker. Bilderna…
-

All tystnad från Sveriges Radio P2
För en tid sedan tog jag tjuren vid hornen och byggde ett site som samlar all tystnad från P2. Om du, som jag, lyssnar en del på denna radiokanal kanske ni också tänkt på att de tillåter mycket mer tystnad än andra kanaler. Det är konstpauser, utklingande stråkkonserter och på det hela taget en mycket större…
-
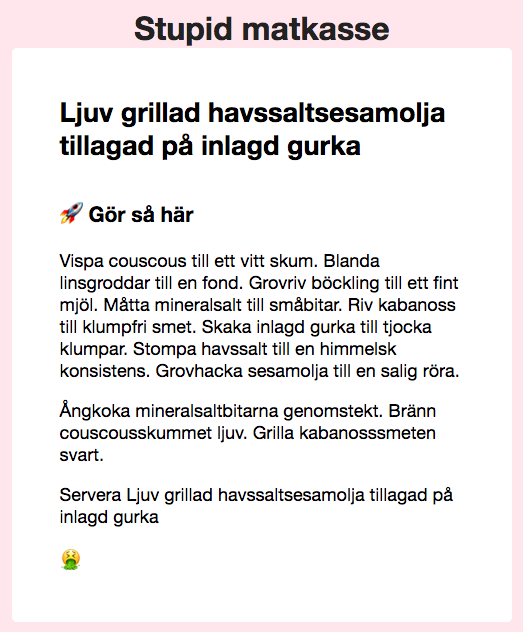
Stupid matkasse
Trenden med färdiga matkassar är ett hot mot vår nyfikenhet och kreativitet i köket. Alla lagar samma mat. Snart har hela svenska hemkökets utveckling stagnerat helt. Exakt det tänkte jag inte, när jag bestämde mig för att göra mitt (prisvinnande!) hack på årets Stupid Hackathon. Jag tänkte nog bara att det kanske kunde bli lite…
-

Kryptosemla – ät en semla in the blockchain
Efter semmelwrap och nachosemla kommer nu Kryptosemlan! Du kan äntligen äta en semla in the blockchain. Mining av krytposemlan sker genom att vispa fram och tillbaka på skärmen, och mjölksyran i armen blir alltså ditt proof of work. Du kan äta en kryptosemla, eller ge bort den till någon annan. I bakgrunden ligger en blockchain…
-

vabruari.sucks
Alla småbarnsföräldrar vet hur vidrig februari är. Förskolorna svämmar över av bakterier och antalet kompletta arbetsdagar går räkna på en hand. På förskolornas ytterdörrar sitter alltid lappar med information om vilka sjukdomar som går för tillfället. Till årets Stupid Hackathon valde vi att tolka den känslan genom att göra en förskolelappsgenerator – Vabruari. Den hämtar in sjukdomar…
-

Stupid Hackathon – again
Last february ~70 people got together and built some very weird stuff; a chatroulette clone for castanets, captchas to keep out cats, big data butt probes, tinder for woodpeckers and gah, so much more. Personally, my fondest memory was the inclusive and jolly feeling. It truly felt like these 70 attendees are the great minds of our generation…
-

Motion tracking for DOOH
Earth People was approached by Forsman & Bodenfors to make a Digital Out Of Home (DOOH) screen come to life. The objective of the campaign was to showcase the client’s eye makeup products. The eyes were shot in 4k and our task was to make these eyes “look” at any motion in front of the screen. Kinect…
-

SXSW Music Discovery
This year we decided to go to SXSW. It’s been a couple of years since last time, so I really hoped that the artist lineup and music schedule would be more comprehensible than it was last time we went. It wasn’t. To make sense of all this data, it needs personalization. Humans tend to be…
-
Our new tool finds “hidden” WordPress pages exposed by just released WP REST API
In December WordPress 4.7 was released. The most cool part of this release was the inclusion of the WordPress REST API. In development for quite some time it was finally included in core. The WordPress REST API is great for developers because it makes it very easy to get all pages, posts and users from…
-

Giphy reactions via SMS on an old CRT
Audience participation during a conference is tricky. You want it to be relevant so it’ll have to be some kind of tech that responds quickly. And at the same time it should be moderated, since the audience can write offensive stuff. Tricky stuff. For our track at Internetdagarna I’ve built a little something that hopefully does this,…
-

Creative Technology @ Internetdagarna
Just after my blog post about how my family uses Slack, the nice people at IIS asked if I wanted to host a track at Internetdagarna in November. Since the blog post came about while misusing technology, I figured the track should be about this. The name of the track: Creative Technology (because that’s the fancy name for goofing around with web stuff).…