So we made a game for Robyn and Red Bull. This is the first in a series of posts about this. Here we focus on the server side and outline some of the challenges we had.
Post nr 1: This post.
Post nr 2: The making of…
Post nr 3: The design of…
While the game itself was a success, we did struggle with something we usually never struggle with – the server side. The nature of the campaign meant that we had huge traffic spikes, which in all honesty we were not prepared for.
Early in the project we decided to write the server side in NodeJS. We’d be hosting this at DigitalOcean, using their load balancer to spread the load round robin among n app servers. Since the campaign period only was ~3 weeks we decided to have a big single database server, running MongoDB.

DigitalOcean
DigitalOcean performed great. Their API’s and GUI’s for taking snapshots of app servers, and creating new droplets is easy and we could easily take servers in and out of rotation using their tag system. Even when they were doing network maintenance we just noted a tiny bit of latency. Something that could have become an issue was the internal network speed on the network. 1Gbps is not that much, and we we’re dangerously close (~800Mbps…) a few times. We would we have had to shard the database if the campaign had stretched for another week.
NodeJS
We ran our node processes via final-pm, and could run as many processes as we had cores on the appservers. This worked pretty great. All app servers sent their logs to Loggly, so we could follow everything in near real time.
Workers
All heavy lifting was offloaded to a couple of worker servers. They were running Agenda and handled achivements, sending push messages and calculate user score. They worked really hard every now and then, which is great, but we started adding some interval between queue jobs to give MongoDB some breathing room.
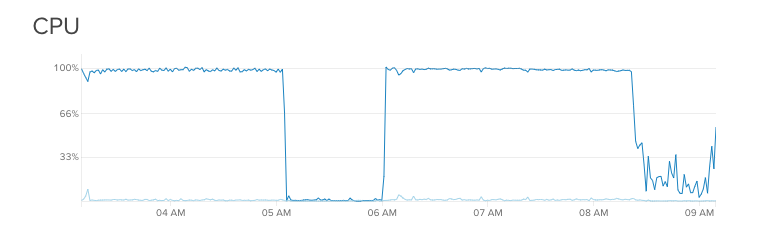
MongoDB
This is where we had some challenges.
First, we didn’t log slow queries on our production database. As the collections grew, response time went up. As there were no logs of this, we didn’t realize this as fast as we hoped. When enabled, the logs showed us that we were missing a few indexes, and when adding these the query time become much more stable.
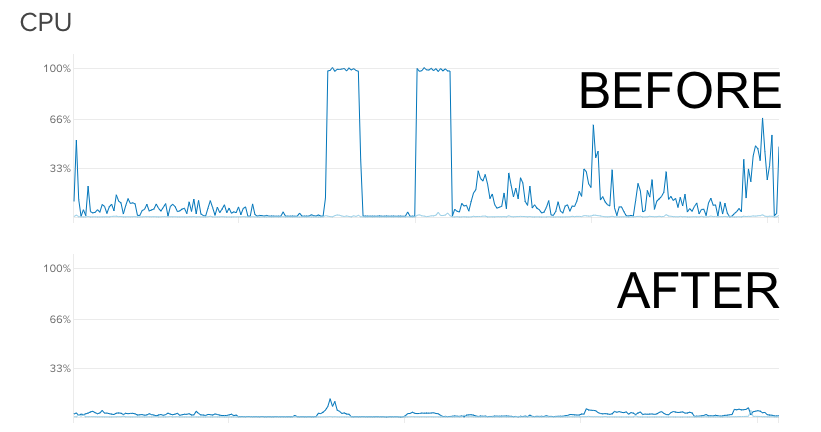
Secondly, using an ORM is a very convenient way to make too many heavy queries and not seeing exactly what queries generates locks… after looking at the raw queries we were able to optimise these.
Thirdly, we did not stress test the API with the same kind of requests as the app did. Since the app updated user position every couple of seconds we had a lot of writes going on at the same time, generating locks.
Key learnings:
- If you use an ORM, make sure you know what queries are being made.
- Make sure to stress test the API with a script that mimics the actual client scenario.
- Make the client handle a slowly responding API gracefully.
- It takes a beta period for testing in order to get things perfect…
As always, it feels sad taking down the cluster just when it performs at it’s peak. Which is now. Good bye cluster. You were great, at the end at least.
Comments
2 responses to “Lessons from making the server side to Red Bull Secret Gig X Robyn”
Is there a reason you went for DigitalOcean and not for the established players like Microsoft Azure or Amazon Web Services?
tbh i’m tired of pasting json configs into textareas at aws and wanted to try something else. glad we gave DO a shot!