Du är besökare 42133
-
Svenska influerare smälter samman när vi återskapar ikonisk videoeffekt från 90-talet med Runway AI
Vi har jobbat mycket med Internetstiftelsen genom åren. Bland mycket annat har vi byggt en gedigen plattform för den årliga undersökningen Svenskarna och internet, gjort UX, illustrationer och animationer för Digitala lektioner, skapat struktur och design för Internetmuseum mm mm. Nu fick vi uppdraget att skapa en iögonfallande toppvideo till den nya digitala utställningen “Svenska…
-

Redaktören i fokus!
Redaktörens roll tas ibland för given, men för en större webbplats eller en digital plattform behöver arbetsflödet fungera för att redaktören ska kunna göra rätt saker. I vårt arbete involverar vi redaktörsbehoven redan i förstudien och sedan hela vägen till färdig produkt. Det ska gå att jobba fritt och effektivt, med tydliga ramar och tillräcklig…
-

Yay, digitala verktyg!
Vi har under ett par år jobbat med ett företag som skulle dra igång en sido-startup. De hade vissa bitar på plats, men jobbade otroligt manuellt. Klippte och klistrade värden, laddade upp filer och pusslade ihop ett resultat. De var en förebild i hur det går att jobba med en tjänst innan infrastrukturen riktigt finns,…
-
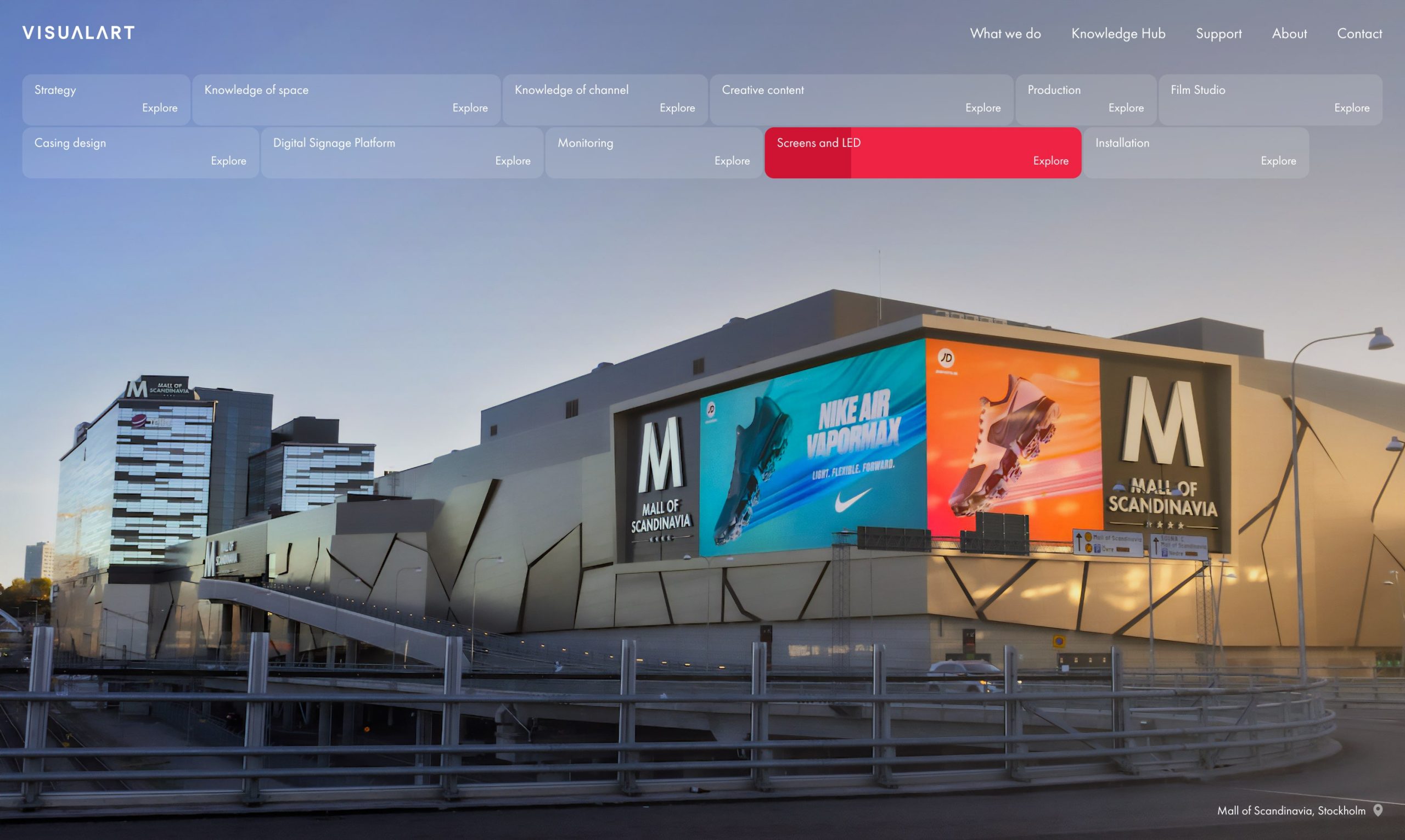
Nya visualart.com – allt från läder och strategi till LED och guld
Earth People har en långvarig relation med Visual Art och har varit en betrodd samarbetspartner under mer än ett decennium. Tidigare samarbeten har resulterat både i webbplats och medskapandet av Visual Arts produkter och interna verktyg. De senaste åren har Visual Art växt så det knakar, både i storlek och vad gäller mängden tjänster de…
-
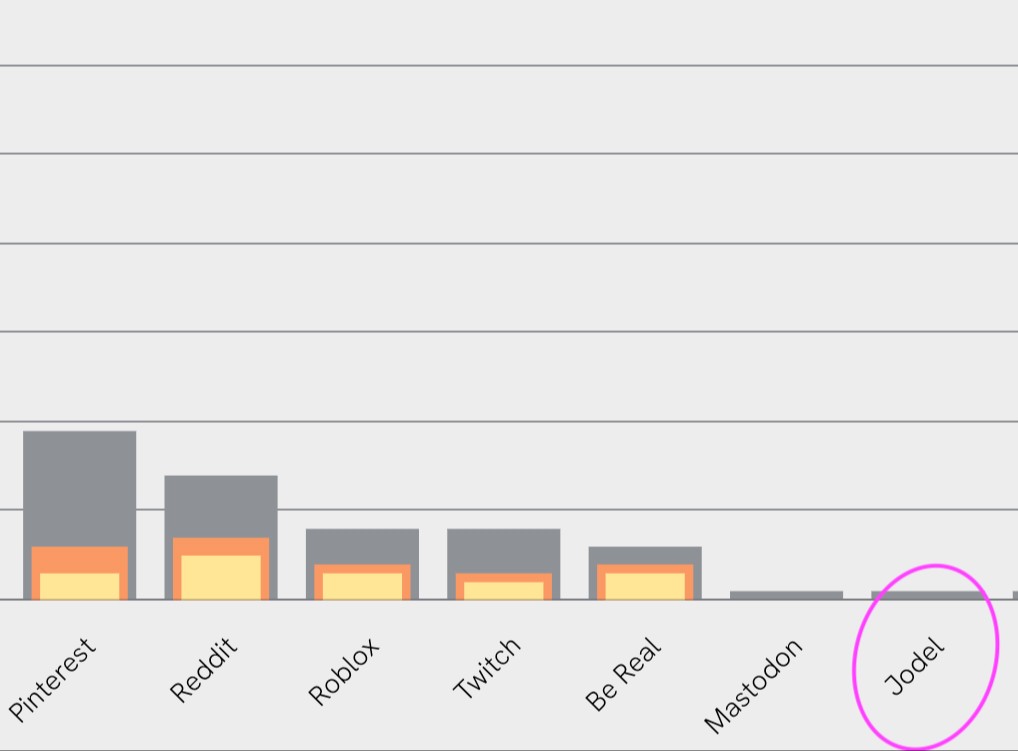
Svenskarna och internet – Jodel!
Vår favvo-grupp av människor från rapporten Svenskarna och internet (vi byggde siten!) – De som 2023 använt Jodel minst någon gång senaste 12 månaderna.
-
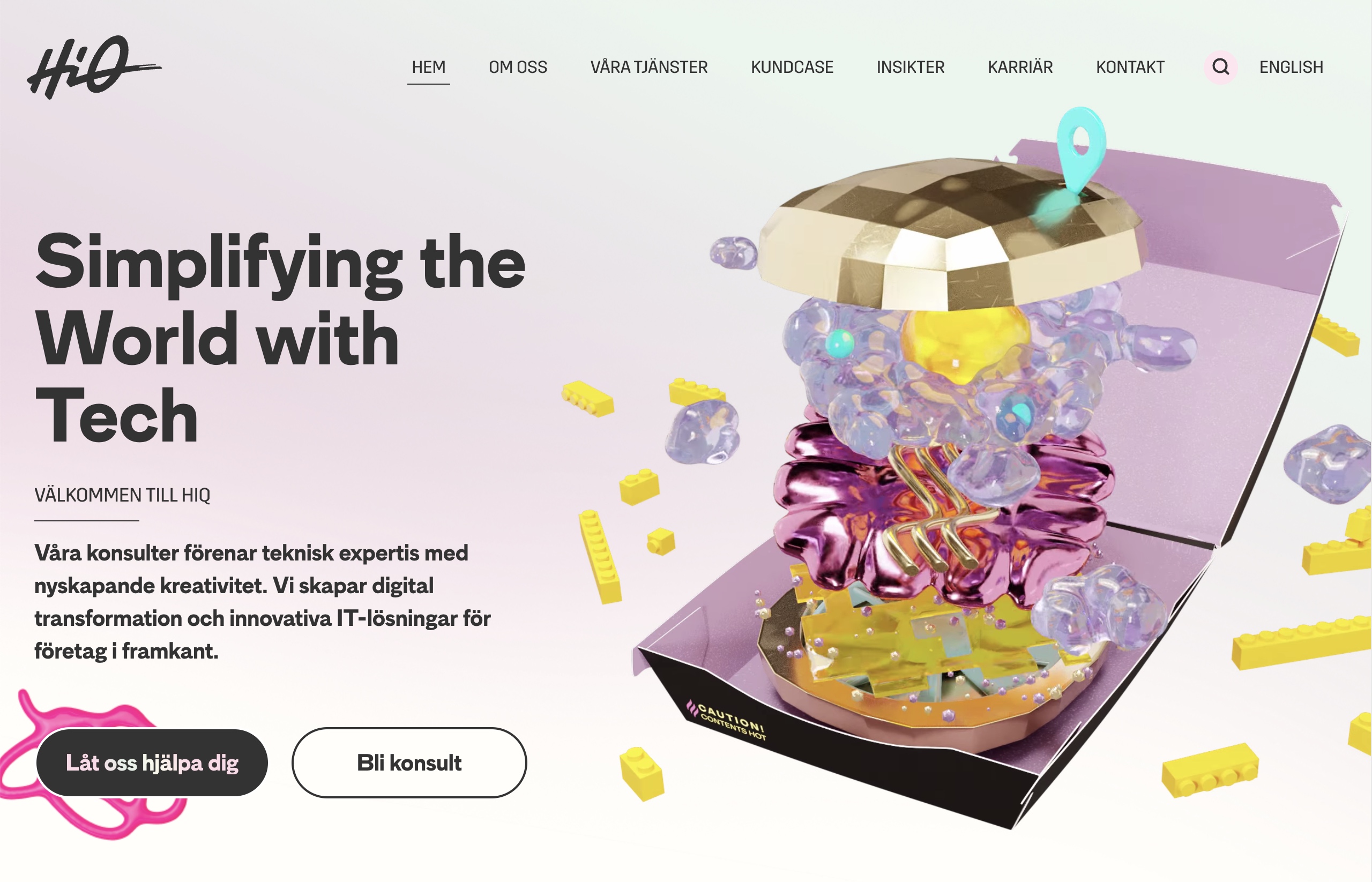
Nominering i Svenska Designpriset!
Earth People är med i två kategorier i Svenska Designpriset, för vårt arbete med HiQ. Dels för deras nya grafiska identitet och dels för själva webbplatsen. Mycket roligt!
-
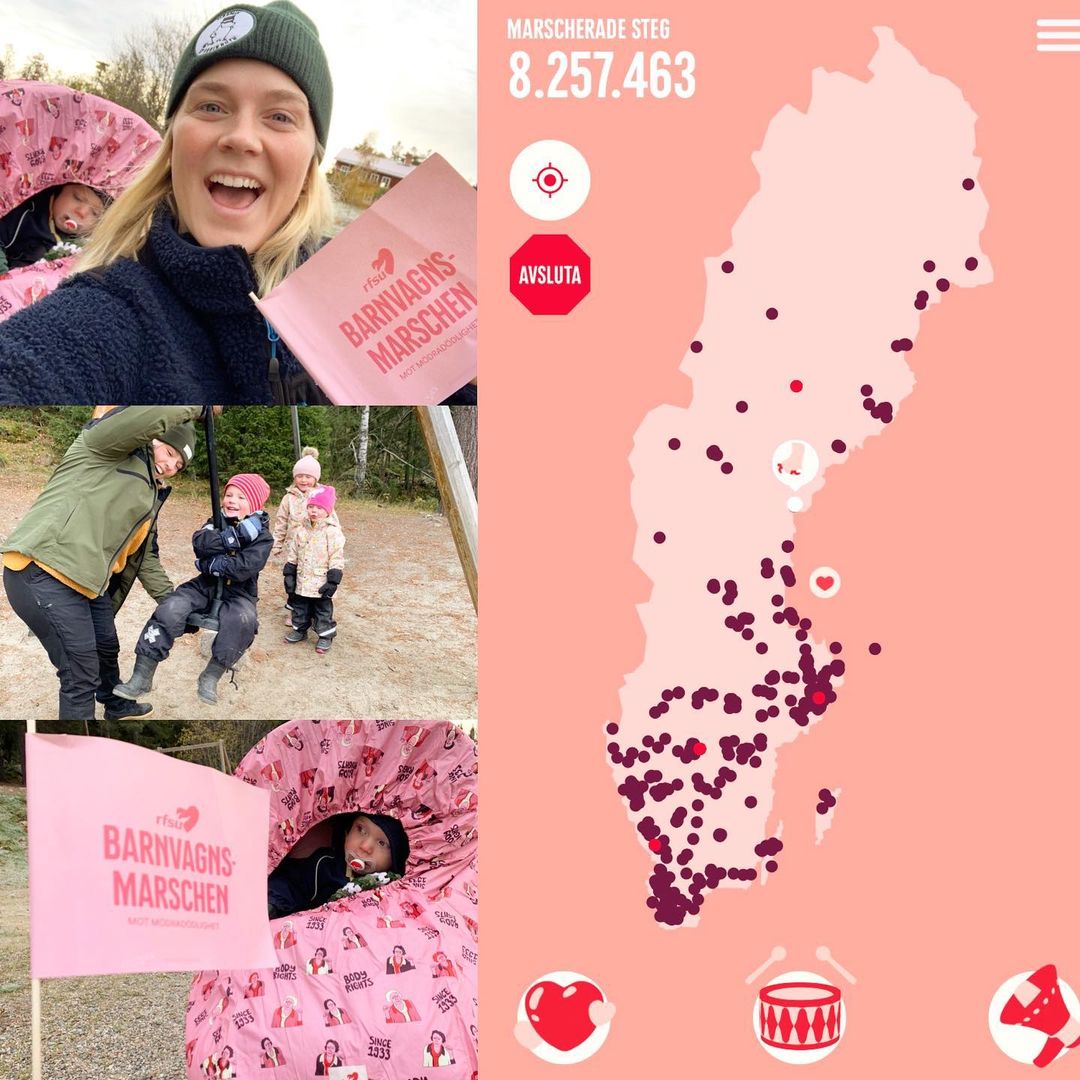
Earth People gör RFSUs barnvagnsmarsch digital
RFSUs Barnvagnsmarsch uppmärksammar mödradödlighet, och har existerat i ett flertal år med fysiska marscher på många ställen runt om i landet. När pandemin satt stopp för fysiska events i grupp skapar istället en webb-app gemenskap och pepp mellan alla som marscherar på egen hand. Pepp och kärlek skickas ut till andra som går och ens…
-

Musik som om det vore 1999
I mars 1999 startades en onlinelabel för elektronisk musik. Det var i Umeå och vi som drev den, Fredrik Mjelle och Sakarias Wangefjord, var båda djs i ett gäng som hade ordnat klubbar och konserter på olika ställen sedan några år tillbaka. En typisk kväll: Sakarias körde Drum n bass på dansgolvet, Erik Hedström och…
-
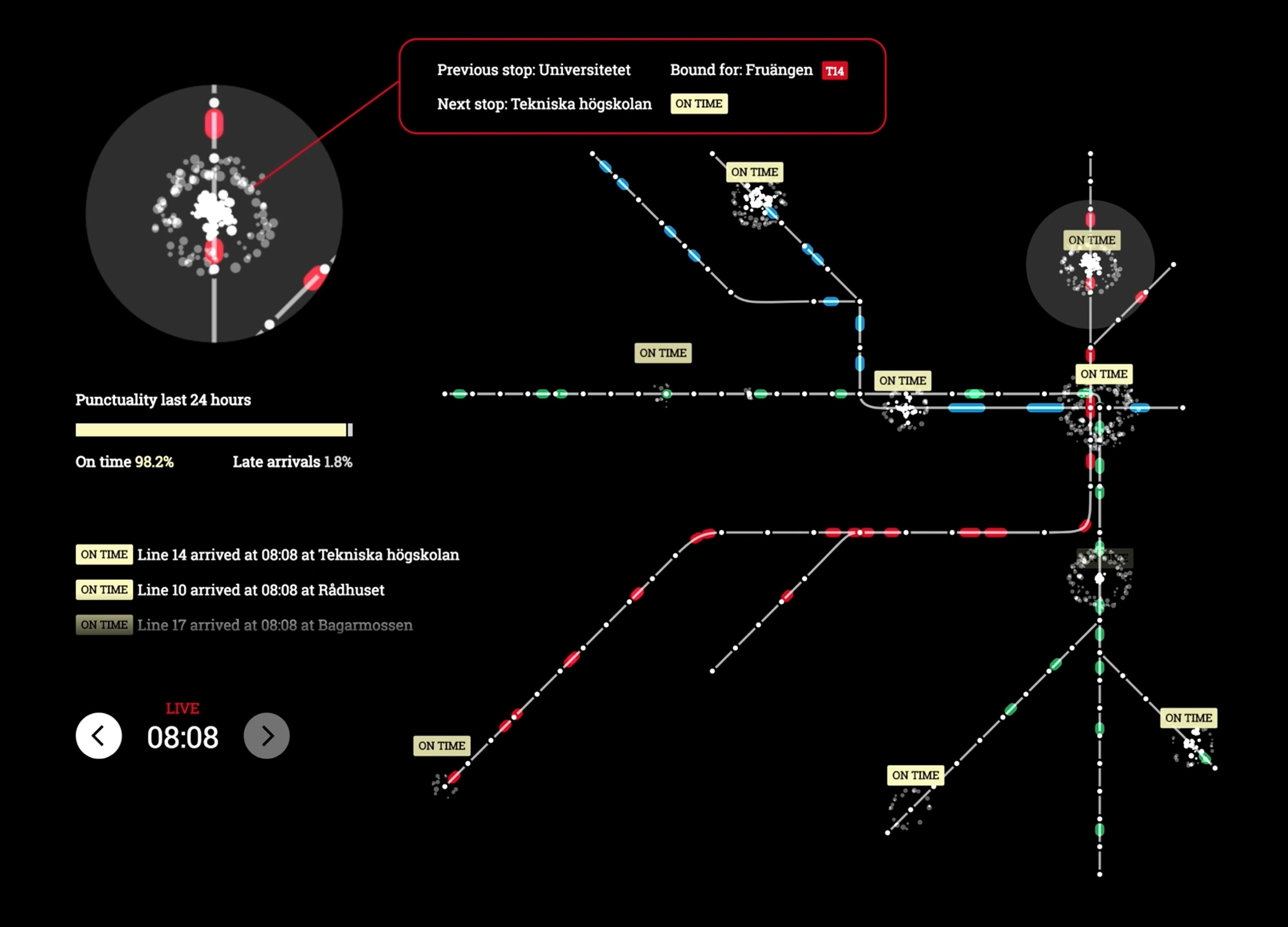
Sound of MTR
MTR and Kärnhuset asked us to do an installation for the Global Public Transport Summit in Stockholm June 2019. Something audio visual, focusing on the SL subway, highlighting the timeliness that it actually has. We wanted to build something where the rhythm of the trains and the passengers came through, a musical reflection of the…
-

New web shop for 1x
1x, the high-end photo community, wanted to broaden their business proposal and start selling art prints by its members directly to the consumer market. Earth People was hired to design and build the frontend for their brand new web shop in close co-operation with 1x who builds and maintains the backend across the community and…
-

I AM SAFE SECURE ENCOURAGED
Sidoprojekt: Labeln Ausland i Portland släpper skiva i samarbete med Earth People. Viktor hos oss har gjort typografi ovanpå LA-designern Lenore Melos bilder, och Fredrik hos oss producerar musiken under namnet Beem. På skivan finns vokala genier som Bahamadia, Philadelphia-legenden som är en av de fetaste klassiska rösterna inom hiphop öht, jobbat med DJ Premier,…
-

Make all videos fun to watch
For this year’s Stupid Hackathon we made a fun little thing called Laff track. Many TV series we know and love wouldn’t be the same without added laughter. There’s a great episode of 99% Invisible about all of this. Our project Laff track is a plugin to Chrome, which adds this craziness to all Youtube…